
























As an artist, I believe that creativity has no boundaries, and that we should embrace all available tools and techniques to bring our visions to life. In today's rapidly evolving world, one such tool that has emerged as a game-changer in the art world is artificial intelligence (AI).
While some may see AI as a threat, I believe that it is a valuable tool that can unleash new forms of creativity and expression.
As artists, we may explore and learn more about AI to fully realize its potential and discover new ways of creating art that push the boundaries of what is possible.
In this blog post, we'll discover this AI tool together, the Stable Diffusion!

What is Stable Diffusion and How Does It Work?

Like the other generative AI such as DALL-E and Midjourney, Stable Diffusion is one of the most popular artificial intelligences that can generate images based on the narration text, so called “text-to-image”.
However, in contrast to DALL-E and Midjourney, which could only be used with cloud services, Stable Diffusion can be run on the majority of consumer-grade hardware as long as it has a modest GPU and at least 4GB of VRAM!
🎉 AI PROMPT VAULT for ANIME ARTIST !
Let's access a Notion document where I share all of my AI generated images with all the “prompts” I used to create them!

Unleash your inspiration with these Midjourney AI prompts! With over 100+ curated prompts, you'll have all the inspiration you need to fire up your creative process. Plus, with our constantly updating prompts and recommended keywords, you'll never run out of ideas. And for a limited time, get access to all of this for just $5 before the price goes up! Click here to access now.
There are numerous articles on the internet that explain how Stable Diffusion works in computer engineering terms. The good news is that you do not need to understand those technical details to make it work.
There are two primary applications for Stable Diffusion:
- create images with text, and
- modify images with text.
In this post, we'll mainly focus on the Stable Diffusion installation and how you can create your first image from it. Let's get started!
PC System Requirements for Stable Diffusion (Local Machine)
Minimum PC specs for Stable Diffusion
- Minimum requirement: In general, Stable Diffusion WebUI requires a PC with the following specifications:
- Operating system: Windows, MacOS, or Linux
- Graphics card: at least 4GB of VRAM, more than 8GB is recommended
- Disk space: at least 12GB free space.
Ideal PC specs for Stable Diffusion
The greater the amount of VRAM, the faster and larger the image can be generated. A good GPU, on the other hand, is more expensive; 12GB of VRAM should suffice. Furthermore, by using Nvidia GPUs, you can use xformers, which speeds up rendering. SSD drives are recommended for hard drives.
Can I run Stable Diffusion on Mac?
You have several options to use Stable Diffusion on Mac, each with advantages and disadvantages.
| Installation | Process | Feature |
|---|---|---|
| Draw Things | Easy | Good, but not as extensive as AUTOMATIC1111 |
| Diffusers | Easy | Models and customization options are limited. |
| DiffusionBee | Relatively easy | Some features are missing. |
| AUTOMATIC1111 | Difficult | The best features of all apps |
What if I don't have a PC or Mac? Can I run Stable Diffusion on my smart phone?
Sure! Thanks to Draw Things, you may run Stable Diffusion on your iPhone 11 and higher for free via the App Store. The app has an impressive number of features that the developer has integrated.
Make AI Art is another free app for Android devices that provides access to Stable Diffusion AI text to image conversion. It makes use of the Stable Diffusion AI that runs on their cloud servers, so it has no effect on the performance of your Android phone.
How to Install Stable Diffusion on Windows (AUTOMATIC1111)
Installing Stable Diffusion on Windows can be a daunting task for those who are new to the world of AI and programming. However, we've summed up all you need! This step-by-step guide makes it quick and simple for anyone to get up and running with Stable Diffusion on their Windows system.
Step 1: Install python
Click here to download Python 3.10.6 and run the installer, make sure to check the “Add Python 3.10 to PATH” box and then click “Install Now” button. (You can check the latest Python version on Python.org)

Step 2: Install git
Click here to download Git. Just run the installer and follow the default setting to complete the installation.
Step 3: Clone web-ui
1. Create a folder: Let's create a folder you want to install Stable Diffusion, then enter the folder.
2. Enter command prompt: Over the directory bar above, type “CMD” then press Enter to enter the command prompt
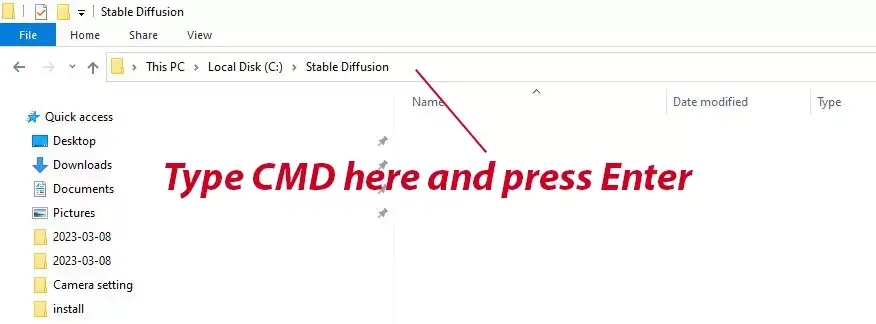
3. Input the command: Type the following command and press Enter
“git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git”

It will take a while to download the Stable Diffusion, if everything goes well, you should see a stable-diffusion-webui folder in your home directory.
Now, you may run Stable Diffusion via the file named “webui-user.bat”. After you open that file, there'll be a command prompt window that opens up. You just need to copy your local address URL and enter the local URL into your web browser (e.g., Chrome, Firefox, Opera, etc.) to run Stable Diffusion.
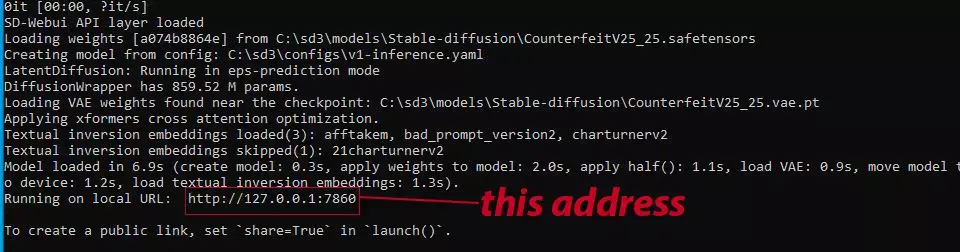

After the installation, you'll get the Stable Diffusion interface like this.
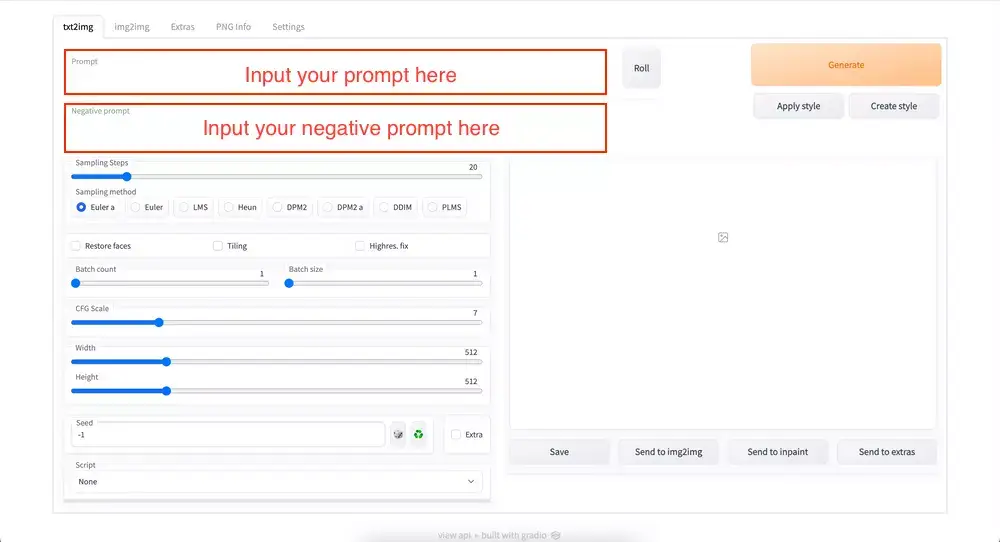
Now, you're ready for the next step. In the next part, we'll introduce you to the Stable Diffusion model.
What is Stable Diffusion Model and Where to Download Them?
The Stable Diffusion model allows you to create new images by using a text prompt that describes which elements should be included or excluded from the output.
There are numerous models to choose. You can use each model to generate images in a variety of styles, including anime style images, cartoon images, realistic images, watercolor paintings, oil paintings, vector art and so on.
The Stable Diffusion Model can be divided into two categories
#1 Main models
Main models, so called Checkpoints, come with files extension of .SafeTensor or .Ckpt (if both are available, choose the .SafeTensor extension as the other might be embedded with an harmful Script). It is a primary model to use the Stable Diffusion.
I would recommend downloading the model from these websites:
1. CivitAi: There're a lot of illustration with lots of reviews.
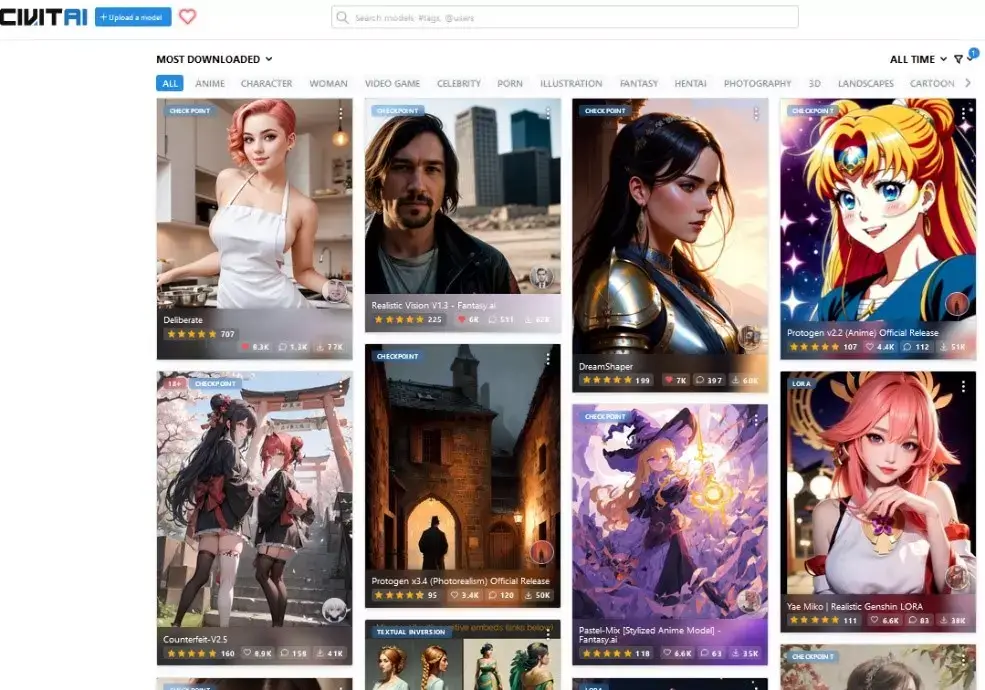
2. Hugging Face: Hugging face is full of models but not with many illustration.
#2 Additional models
This kind of model is optional. Actually, you can use only the main model to generate images. However, adding the additional model will give you a more specific and better result.
1. LoRA (Low-Rank Adaptation)
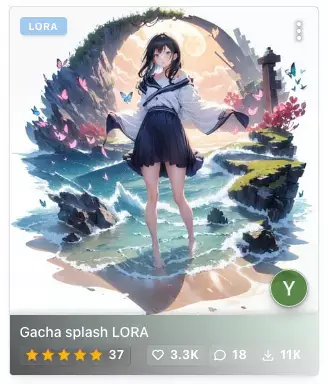
LoRA is an additional model that provides very good quality to the majority of users, with a file size of about 100 MB, which is very small compared to Checkpoints.LoRA model type is used when you need a specific outcome in your generated images. For example, the specific object, art style, costume, character, or so on.You can find LoRA model from Civitai by using the filter in the search bar.
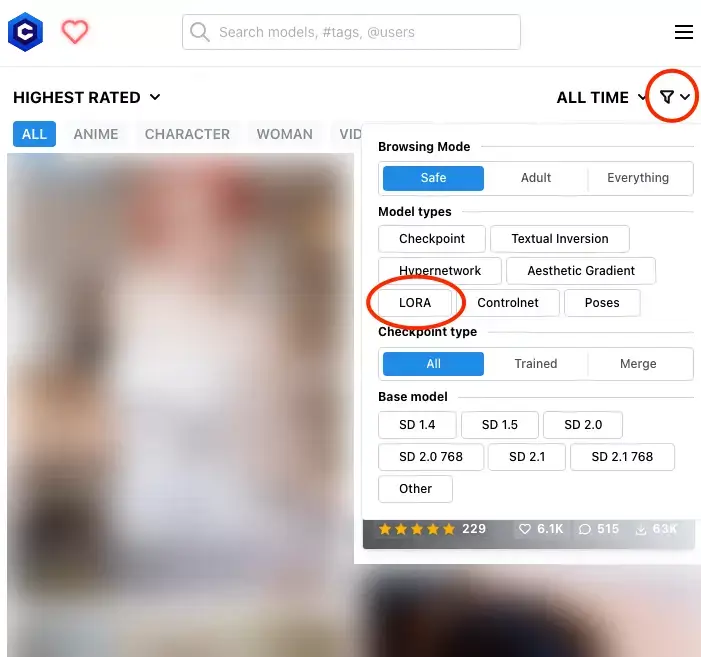
There are many different LoRA files available to choose from, such as a gun LoRA to provide the proper design of a gun and a Gacha splash art style LoRA that will give you a splash art image style. LoRA seems to be a popular additional model for Stable Diffusion since it's easy to train and you can train your own LoRA with any images you want on you PC or Google Colab.
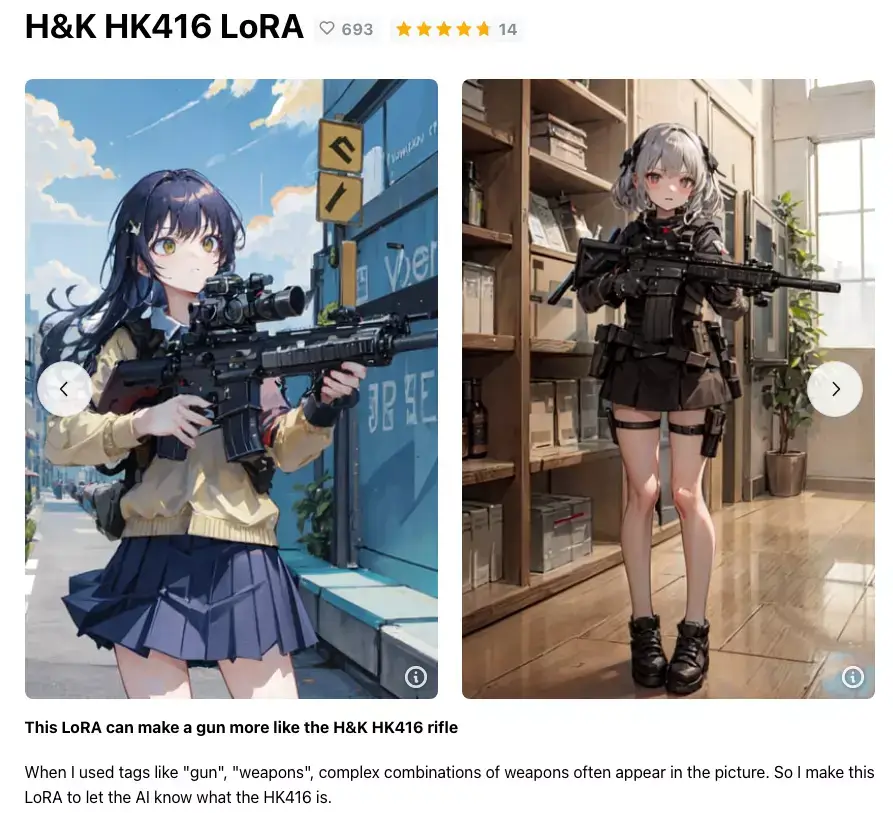
2. Textual Inversions
Textual Inversion is for capturing novel concepts from a small number of example images in a way that can later be used to control text-to-image pipelines. It is a very small additional model (size 10-100 KB), but the quality is not comparable to LoRA.
You have the option of picking either LoRA or Textual Inversions as the additional model. Each one or both of them can be used. Despite this, the LoRA is a far more preferred option.
Where to put the Downloaded Stable Diffusion Model?
After downloading the model, place the downloaded files to the following folder:
Main models files: place it in the “stable-diffusion-webui\models\Stable-diffusion” folder.
LoRA files: place it in the “stable-diffusion-webui\models\Lora” folder
Textual Inversions: place it in the “stable-diffusion-webui\embeddings” folder
How can I use Stable Diffusion?
OK, we can now begin using the Stable Diffusion! It only takes three simple actions to create your first image in Stable Diffusion. Let's follow these steps to start generating your own.
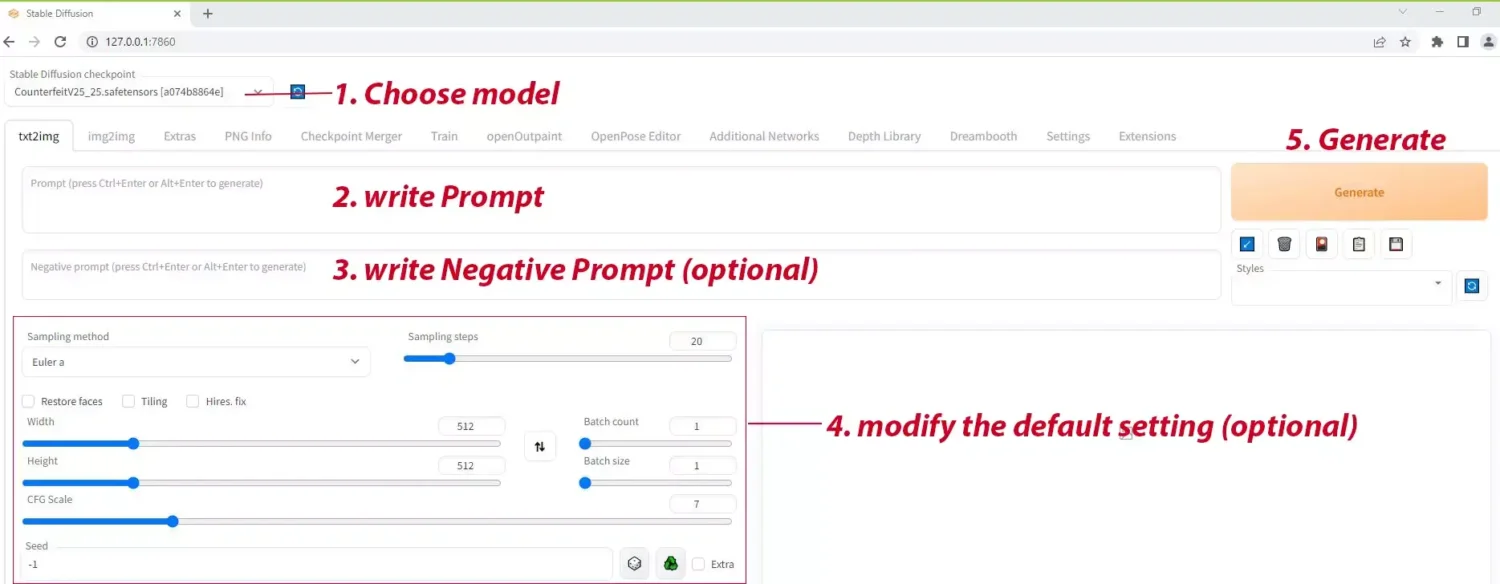
STEP #1: Choose the model
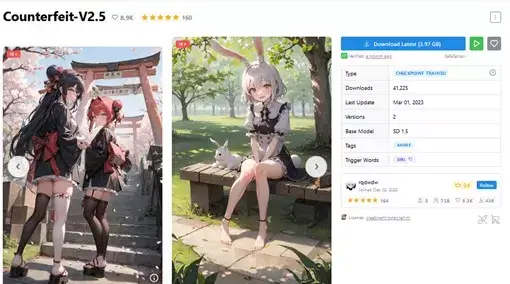
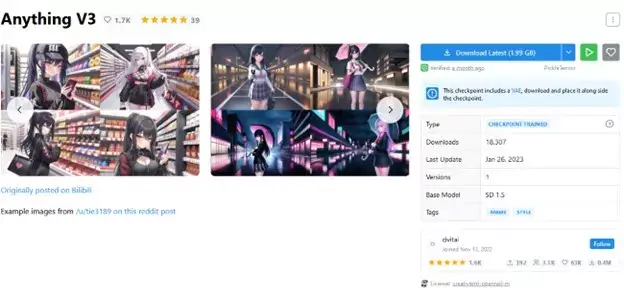
The first thing that we need to do is choose the model in accordance with your style preferences (i.e., photorealistic or anime). The following are the popular models for anime style:
STEP #2: Write the Prompt
There are two distinct prompt types used to generate AI images: the first is a standard prompt, while the second is a negative prompt.
Prompt: Prompt is a text string that we feed to the system to generate an image. In general, the more particular information you supply, the better the results will be. If you want the AI to focus on a certain word, use parenthesis to emphasize the words.
Here is the example of the Stable Diffusion prompt:
(extreme long shot), masterpiece, best quality, best work,(1girl), beautiful female warrior, standing in forest, fisheye distortion
If you run out of ideas to create your own prompt, you can use some tags from our Anime Girl Prompt Guide. It's a prompt guide for NovelAI, but the tags and keywords can be used in Stable Diffusion too since NovelAI is running the Stable Diffusion under the hood!
Negative Prompt: You can input “negative prompt” in a box under the “normal prompt.” The Negative prompt is what we don't want in the image. For example, if you don’t want a realistic photo, we would put this word in the negative prompt.
STEP #3: Modify the settings
Sampling method
With the same prompt and other settings, different sampling methods may provide different results; you may play around with the sampling methods and see which one is suitable for your style.
Sampling steps
This one determines how many noise removal iterations will be performed. The more steps there are, the better the outcome will be. However, the image does not change significantly after 30 steps. The number of steps also has a direct impact on generation speed.
Width and Height
Stable Diffusion generates images with 512 to 512 pixels by default; you will get the most consistent results with this size. The size can be adjusted, but it will demand more computing power.
CFG Scale
The CFG Scale determines how closely Stable Diffusion will follow your prompt. A higher value forces the AI to closely follow the prompt, whereas a lower value allows the AI more freedom.
It is recommended to use the default value of 7.5 rather than the extreme values of 0 or 20.
Seed
Seed is in charge of generating the initial noise used to generate the image. The same seed will always generate the same image, while different seeds will generate different images. If you enter the seed at -1, it will be generated at random.
Batch count
Batch count will set the number of batches to run sequentially. The batch size specifies the number of parallel images in each batch. Please note that parallel image processing will consume more memory.
After you write the prompt and have all settings in place, just click the “Generate” button to see your result.
Let's see our generated images with the prompt and settings below!

Prompt:
(extreme long shot), masterpiece,best quality,best work,(1girl), beautiful female warrior, standing in forest, fisheye distortion
Steps: 20
Sampler: DPM++ 2M Karras
CFG scale: 10
Seed: 2285623379
Size: 768×512
Model hash: 812cd9f9d9
Model: anythingV3_fp16
Denoising strength: 0.7

Prompt:
(extreme long shot), from below, masterpiece, best quality, best work,(1girl), beautiful female mage, standing in holy sanctuary, fisheye distortion
Steps: 20
Sampler: DPM++ 2M Karras
CFG scale: 10
Seed: 3963221518
Size: 768×512
Model hash: a074b8864e
Model: CounterfeitV25_25
Denoising strength: 0.7

Prompt:
((extreme long shot)), masterpiece, best quality, best work,(1girl), beautiful maid, gray hair, standing in luxury hotel room, (fisheye distortion)
Steps: 20
Scale: 11
Sampler: DPM++ 2M Karras
CFG scale: 10
Seed: 3748225627
Size: 768×512
Model hash: a074b8864e
Model: CounterfeitV25_25
Denoising strength: 0.7
Congratulations, you have reached the end of our Beginner's Guide to Stable Diffusion! We hope that this guide has provided you with the knowledge and skills needed to take your first step in using this powerful AI tool.
In conclusion, AI has become an increasingly important tool for artists looking to enhance their creative capabilities. With its ability to generate high-quality images and offer new perspectives on the creative process, AI is transforming the art world in unprecedented ways.
Stable Diffusion is one such AI tool that is particularly useful for artists, allowing them to generate stunning and unique images with ease. By embracing AI and exploring the various techniques it has to offer, artists can tap into a new world of creativity and unlock the full potential of their artistic vision. So if you're an artist looking to take your work to the next level, don't hesitate to explore the possibilities of AI and see how it can transform your artistic process!

Finally, if you like art tips and content like this, feel free to subscribe to my weekly newsletter: MiMi Art Tips!
I share my anime art tips and experiences in my digital art career in a weekly email. You'll get the insight and behind the scene of the art career! Really recommend if you're a beginner anime style artist. Click here to subscribe!
Thank you so much for reading this post! I really appreciate your visiting and using your valuable time reading my content!
Much Love 💖

Want to know how to start your anime art journey?
Download my ANIME ART STARTER GUIDE and start your artistic path right away for FREE!